Contents
- Introduction
- Data Science
- How does Data Science work? : Data Science at UBER
- Data Science Process
- Data Collection
- Data Cleaning
- Data Exploration
- Data Modeling
- Data Validation
- Data Deployment & Optimization
- Data Science Applications
- Example 1
- Example 2
- Data Scientist
- Data Scientist Job Trends
- Data Scientist Skills
Introduction
We hear a lot about how artificial intelligence and machine learning are going to change the world, and how the internet of things will make everyone’s life easier, but what’s the one thing that underpins all of these revolutionary Technologies? The answer is data.
From social media to IoT devices. We’re generating an immeasurable amount of data. Consider the cab service provider Uber. I’m sure all of you have used Uber. What do you think makes Uber a multi-billion dollar worth company? Is it the availability of cabs or is it their service? The answer is data, data makes them very rich but wait, is data enough to grow a business of course not, you must know how to use the data to draw useful insights and solve problems. This is where data science comes in.
Data Science
Data science is the process of using data to find Solutions or predict outcomes for a problem statement.
How does Data Science work? : Data Science at UBER
To better understand data science, let’s see how it affects our day-to-day activities. It’s a Monday morning and I have to get to the office before my meeting starts, so I quickly open up Uber and look for cabs, but there’s something unusual the cab rates are comparatively higher at this hour of the day. why does this happen?
Well obviously because Monday mornings are peak hours and everyone is rushing off to work the high demand for cabs leads to an increase in cab fares. We all know this but how is all of this implemented? Data science is at the heart of Uber’s pricing algorithm. The Surge pricing algorithm ensures that its passengers always get a ride when they need one even if it comes at the cost of inflated prices. Uber implements data science to find out which neighborhoods will be the busiest so that it can activate search pricing to get more drivers on the road. In this manner, Uber maximizes the number of rides it can provide and hence benefit from this.
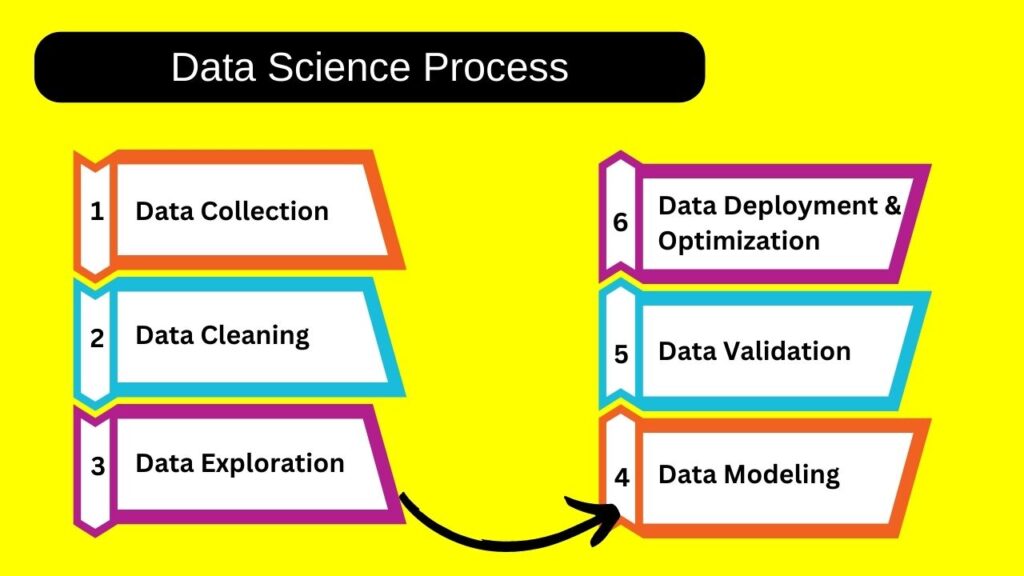
Data Science Process
The data science process always begins with understanding the business requirement or the problem you’re trying to solve. In this case, the business requirement is to build a dynamic pricing model that takes effect when a lot of people in the same area are requesting rides at the same time.
Data Collection
Uber collects data such as the weather, historical data, holidays, time, traffic, pickup and drop location and it keeps a track of all of this.
Data Cleaning
Sometimes unnecessary data is collected such data only increases the complexity of the problem, an example is Uber might collect information like the location of restaurants and cafes nearby. Now such data is not needed to analyze Uber search pricing, therefore such data has to be removed at this step.
Data cleaning is followed by data Exploration and Analysis :
Data Exploration
The data exploration stage is like the brainstorming of data analysis. This is where you understand the patterns in your data.
Data Modeling
The data modeling stage basically includes building a machine learning model that predicts the Uber search at a given time and location. This model is built by using all the insights and Trends collected in the exploration stage. The model is trained by feeding thousands of customer records so that it can learn to predict the outcome more precisely.
Data Validation
Here the model is tested when a new customer books a ride. The data of the new booking is compared with the historic data in order to check if there are any anomalies in the search prices or any false predictions. If any such anomalies are detected a notification is immediately sent to the data scientists at Uber who fix the issue. This is how Uber predicts the search price for a given location and time.
Data Deployment & Optimization
After testing the model and improving its efficiency. It is deployed on all the users at this stage customer feedback is received and if there are any issues they are fixed here.
Data Science Applications
Data science is implemented in e-commerce platforms like Amazon and Flipkart. It is also the logic behind Netflix’s recommendation system. Now when all actuality data science has made remarkable changes in today’s market, its applications range from credit card fraud detection to self-driving cars and virtual assistants such as Siri and Alexa.
Example 1
Let’s consider an example suppose you look for shoes on Amazon but you do not buy it then and there, now the next day, you’re watching videos on YouTube and suddenly you see an ad for the same item, you switch to Facebook there also you see the same ad. So how does this happen? This happens because Google Tracks your search history and recommends ads based on your search history.
This is one of the coolest applications of data science in fact 35 percent of Amazon’s revenue is generated by product recommendations and the logic behind product recommendations is data science.
Example 2
Let me tell you another such story, Scott Killen never imagined his Apple watch might save his life but that’s exactly what happened a few months ago when he had a heart attack in the middle of the night how could a watch detect a heart attack? Any guesses, well it’s data science again.
Apple used data science to build a watch that monitors an individual’s Health. This watch collects data such as the person’s heart rate, sleep cycle, breathing rate, activity level, blood pressure, etc, And keeps a record of these measures 24 x 7. This collected data is then processed and analyzed to build a model that predicts the risk of a heart attack.
Data Scientist
Why you should become a data scientist? According to Linkedin’s March 2019 survey. A data science scientist is the most promising job role in the US and it stands at number one on Glassdoor’s best jobs of 2019.
Data Scientist Job Trends
Here are a couple of job trends that I collected from LinkedIn top companies like Microsoft, IBM, Facebook, and Google have over a thousand job vacancies and this number is only going to grow.
Similarly, these job Trends show the vacancy of jobs with respect to geography. Coming to the salary of a data scientist the average salary ranges from a hundred thousand dollars to a hundred and eighty-two thousand dollars.
Now, remember that your salary varies on your skills, your level of experience, your geography, and the company you’re working for.
Data Scientist Skills
You must be skilled in statistics and have expertise in programming languages like R and python. These are must you’re required to have a good understanding of processes like data extraction, processing, wrangling, and exploration.
You must also be well versed with the different types of machine learning algorithms and how they work. Advanced machine learning Concepts like deep learning are also needed. You must also possess a good understanding of the different big data processing Frameworks like Hadoop and Spark and finally, you must know how to visualize the data by using tools like Tableau and Power BI.
Do you Know Data Science Helps a lot in Machine Learning? Because Machine Learning uses data to train machine learning models. Read More about Machine Learning
